시퀀스 데이터란 무엇인가?
시퀀스 데이터(Sequential Data)란 시간 순서에 따라 정렬된 데이터를 의미한다. 단순히 나열된 데이터가 아니라 순서와 시간 간격이 의미를 가지는 데이터이다.
예시로는 다음과 같은 것들이 있다:
- 자연어 문장 (단어 순서 중요)
- 음성 데이터 (시간에 따라 파형이 다름)
- 주가 그래프 (과거가 현재에 영향을 미침)
- ECG, EEG와 같은 생체 신호
이런 데이터는 과거 정보가 현재 결과에 영향을 미치는 의존성(dependency)을 가지고 있어서, 일반적인 신경망(FNN, CNN 등)으로는 충분히 처리하기 어렵다.
기존 전통적인 신경망의 한계
기존의 피드포워드 네트워크(Feedforward Neural Network, FFN)는 모든 입력을 독립적으로 처리한다. 즉, 현재 입력이 어떤 순서로 들어왔는지, 이전에 어떤 입력이 있었는지는 고려하지 않는다.
이는 이미지 분류처럼 입력이 고정된 작업에는 적합하지만, 문장 분석이나 음성 인식처럼 순서가 중요한 작업에는 치명적인 단점으로 작용한다. 이러한 한계를 극복하기 위해 RNN이 등장하게 된다.
RNN의 기본 구조
RNN은 기본적으로 다음과 같은 세 가지 층으로 구성된다:

입력층 (Input Layer)
- 각 시점의 입력 데이터를 받아서 은닉층으로 전달한다.
- 자연어 처리에서는 보통 단어 임베딩 벡터가 입력으로 들어온다.
은닉층 (Hidden Layer)
- RNN의 핵심이다. 이전 은닉 상태와 현재 입력을 바탕으로 새로운 은닉 상태를 계산한다.
- 이를 통해 시간 축을 따라 정보를 전달하고 기억할 수 있다.
수식 :

출력층 (Output Layer)
- 은닉 상태를 기반으로 최종 예측값을 생성한다.
- 분류 문제의 경우 softmax, 회귀의 경우 선형 출력층을 사용한다.
Vanilla RNN의 장단점
장점
- 시퀀스 데이터 처리에 적합하다.
- 시간에 따른 문맥(Context)을 학습할 수 있다.
단점
- 기울기 소실(Vanishing Gradient) 문제로 인해 긴 시퀀스를 학습하기 어렵다.
- 계산이 순차적으로 일어나 병렬처리가 어렵고, 학습 속도가 느리다.
LSTM: 장기 의존성 문제의 해결책
LSTM(Long Short-Term Memory)은 RNN의 가장 대표적인 변형 구조이다. 장기 의존성 문제를 해결하기 위해 내부적으로 Cell state(셀 상태)와 3가지 게이트를 사용한다.


구성 요소:
- Forget Gate: 과거 정보 중 어떤 것을 버릴지 결정

- Input Gate: 현재 입력 중 어떤 정보를 저장할지 결정
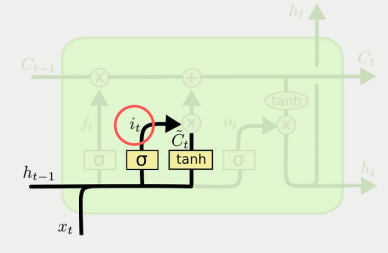
- Output Gate: 다음 단계로 어떤 정보를 전달할지 결정

LSTM은 이 게이트 구조를 통해 중요한 정보를 오랫동안 기억하고, 불필요한 정보를 잊는다. 이를 통해 기울기 소실 문제를 크게 완화할 수 있다.
GRU: 더 간단한 RNN의 대안
GRU(Gated Recurrent Unit)는 LSTM과 유사한 기능을 갖고 있으나, 구조는 더 간단하다.
- Update Gate: 기존 상태를 얼마나 유지할지를 조절
LSTM의 forget gate와 input gate를 합친것과 유사한 역할을 한다.


- Reset Gate: 과거 정보를 얼마나 반영할지를 조절


GRU는 셀 상태와 은닉 상태를 하나로 통합하여 연산량을 줄이고, LSTM보다 빠른 학습 속도를 보여준다. 구조가 단순하다는 점에서 소형 모델에 유리하다.
다양한 입력/출력 구조
RNN은 입력과 출력의 형태에 따라 다음과 같은 방식으로 활용된다:
| 구조 | 예시 | 구조도 |
| One-to-Many | 이미지 캡셔닝 |  |
| Many-to-One | 감성 분석 (문장 → 감정) |  |
| Many-to-Many | 번역, 대화 시스템 등 |  |
학습: BPTT(Backpropagation Through Time)
RNN은 시간축을 따라 네트워크가 연결되므로 일반적인 backpropagation을 그대로 사용할 수 없다. 대신 시간 축으로 네트워크를 펼친 후, 각 시점에서 발생한 오류를 역전파하는 방식인 BPTT를 사용한다.
하지만 이 과정에서 다음과 같은 문제가 발생한다:
기울기 소실
- 반복적인 chain rule로 인해, 초기 시점의 기울기가 0에 수렴
- 긴 시퀀스의 경우 오래된 정보가 무시된다
기울기 폭발
- 기울기가 너무 커져 학습이 불안정해짐
해결책
- Truncated BPTT: 일정 구간까지만 역전파 수행
- Gradient Clipping: 기울기가 임계값 이상일 경우 잘라냄
- LSTM/GRU 사용: 구조 자체로 기울기 문제 완화
정리
| 항목 | Vanilla RNN | LSTM | GRU |
| 구조 | 가장 단순 | 복잡 (3개의 게이트) | 중간 (2개의 게이트) |
| 장기기억 | 어려움 | 가능 | 가능 |
| 계산량 | 낮음 | 높음 | 중간 |
| 속도 | 빠르나 학습 어려움 | 느림 | LSTM보다 빠름 |

RNN은 순차 데이터를 처리하기 위해 만들어진 강력한 구조이다. 자연어 처리, 음성 인식, 시계열 예측 등에서 핵심적인 역할을 한다. LSTM과 GRU는 RNN의 실전 활용성을 높여주는 중요한 변형이며, 특히 긴 시퀀스 문제에 필수적이다.
'인공지능' 카테고리의 다른 글
| Advanced Machine Learning-04 : 선형 회귀 모델(Linear Regression Models) (0) | 2025.04.19 |
|---|---|
| Advanced Machine Learning-03: Probabilistic Distributions (0) | 2025.04.18 |
| Advanced Machine Learning-02 :머신러닝을 위한 수학 및 이론적 기초 다지기 (0) | 2025.04.17 |
| 인공지능의 기초: AI의 개념과 작동 원리 이해하기 (0) | 2024.09.04 |